Holistic testing for open-source models
Note: this documentation was written for an AI platform startup.
Overview
Benchmark leaderboards are often disconnected from production reality. Models can dominate standardized benchmarks and then experience significantly poorer performance when deployed against real world data. This is particularly shown in recent research on GSM8k math problems.
This makes our own testing of open source models for our specific use cases vital.
The top 3 factors for evaluating open source models for our chat and agentic services include:
- Inference latency and throughput under load: For interactive chat, latency directly determines user experience. Producing high-quality outputs at 5+ seconds per response creates an unacceptable user experience. For agentic workflows, inefficient tool-calling patterns create cascading latency and cost impacts that compound across multi-step tasks.
- Task specific accuracy: A model scoring 85% on MMLU may score 60% on your domain-specific tasks.
- Failure Mode Distribution: Models with similar average performance can differ dramatically in the impact of their failures. A model that occasionally hallucinates citations might be acceptable for brainstorming but catastrophic for customer-facing factual queries. Understanding the distribution of failures—not just average performance—is critical.
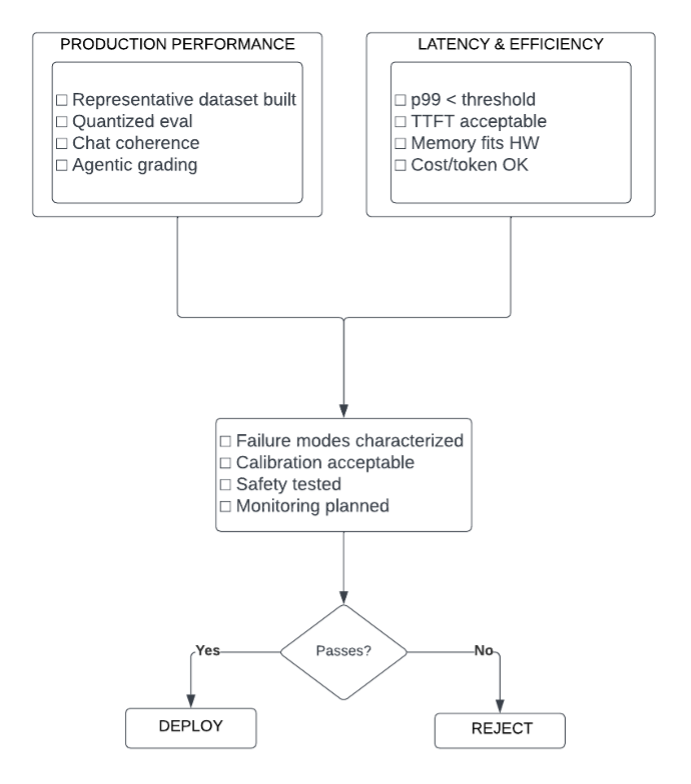
To test open-source models for these factors, we need a holistic review process. One that extends beyond superficial benchmark scores to encompass performance, scalability, efficiency, transparency, risk assessment, and operational characteristics.
Holistic review process
In specifics, we must:
- Evaluate agentic workflows at the transcript level. For inference latency and throughput under load, we must examine full interactions. Task success alone misses inefficient tool-calling, poor error recovery, and instruction drift.Suggest: Measure TTFT and TPS at P50/P95 using vLLM benchmarks under 50/100/200 concurrent requests. Target: TTFT <500ms at P95.
- For task specific accuracy we must:
- Create production-representative test data. We must use representative data that the models did not see in training. This data must match our real-world production data, with representative examples across all categories.
-
- Measure at deployment configuration. Test at target quantization, hardware, and load levels—not idealized conditions.
Suggest: Build held-out test set of 500+ examples across query categories. Measure exact-match, semantic similarity, and format compliance. Compare against the current baseline model in a duplicate of the production system under load.
- Characterize failures, not just averages. To properly evaluate failure mode distribution we must understand which failures are occurring, and how much our service can tolerate them.
Suggest: Classify errors into taxonomy (hallucination, refusal, format error, drift). Measure P99 severity. Compute calibration metrics (ECE).Include adversarial probes such as prompt injection attempts, malformed inputs, and domain edge cases. These can surface failure modes not captured by standard evaluation. Models with similar average performance often diverge dramatically under adversarial conditions.
Proposed Decision Framework
| Criterion | Threshold | Rationale |
| P95 TTFT (at target load) | < 500ms | UX hard constraint for chat |
| Task accuracy (held-out set) | ≥ 70% baseline | Below this, quality is unacceptable |
| Catastrophic failure rate | After categorization of failures, identify most specific and dangerous categories. Ensure that above all else those categories specifically come in at < 0.5%. | Confident hallucinations become harmful outputs at different rates in different categories. |
Weighted Scoring Criteria
| Factor | Weight | Scoring Basis |
| Inference efficiency | 25% | P95 latency, throughput at load, memory footprint |
| Task-specific accuracy | 30% | Held-out test performance, instruction-following, format compliance |
| Failure mode profile | 25% | Error taxonomy distribution, P99 severity, calibration. |
| Agentic competence | 20%
|
Tool-call accuracy, planning efficiency, error recovery |
Tradeoffs and virtual ties
When considering tradeoffs, it’s best to err on the side of low latency and accuracy. When choosing between those two, for now we are prioritizing low latency.
If candidates score within 0.3 points, then apply workload-specific preferences.
- Chat-heavy deployments should favor latency.
- High-stakes domains should favor failure mode profile.
- Cost-constrained environments should favor smaller models meeting thresholds.
Holistic test plan example